DevOps
Ein Artikel von Andreas Kuhn
– Was ist DevOps?
Das Ziel von DevOps ist es, eine gemeinsame Verantwortung zwischen 2 traditionell getrennten Bereichen innerhalb der IT zu erzielen – Entwicklung (DEV) und Betrieb (OPS).
Beide Bereiche verfolgen unterschiedliche Ziele. Daher ist das Verhältnis beider Bereiche zueinander spannungsgeladen.
Das Unternehmen fordert aufgrund des zunehmenden Wettbewerbs in immer kürzeren Frequenzen neue Funktionalitäten innerhalb ihrer Softwarepakete, was den Druck auf die Entwicklung verstärkt (Time to market). Entwickler müssen viel schneller als bisher, in erheblich kürzeren Releasezyklen Software bereitstellen und diese dann auch dem Unternehmen im produktiven Umfeld zur Verfügung stellen.
Hier kommt der Betrieb ins Spiel dessen wichtigste Aufgabe es ist, dass die Software innerhalb der Produktivumgebungen stabil funktioniert, auch bei unterschiedlichen Lasten. Eine einmal laufende Umgebung soll nach Möglichkeit nicht angefasst werden – schließlich wird der Betrieb auch dafür verantwortlich gemacht, wenn die Software einmal nicht tut, was sie tun soll.
Das Motto ist hier oftmals: „never touch a running system“. Kommt es zu Fehlern im Betrieb, ist dies aus Sicht des Betriebs natürlich in erster Linie die Schuld der Entwickler, die neue Features mal wieder nicht sauber getestet haben.
Was ich hier beschrieben habe, ist auch bekannt als „shame game“ oder „blaming culture“ – der immerwährende Streit zwischen Entwicklung und Betrieb. Es scheint ein Naturgesetz zu sein.
Ziel der DevOps-Bewegung ist es, diesen vermeintlichen Gegensatz aufzulösen. Entwicklung und Betrieb soll hier zu einer schlagkräftigen Einheit verschmolzen werden, um Software schneller, sicherer bereitstellen zu können – einen echten Mehrwert für das Unternehmen zu liefern.
Damit dies gelingen kann, muss im Unternehmen eine neue Kultur, ein gemeinsames Verständnis entwickelt werden. John Willis, einer der Veteranen der DevOps-Bewegung nennt 5 Punkte, die im Unternehmen vorhanden sein müssen, damit DevOps überhaupt funktionieren kann.
Beide Abteilungen Dev und Ops müssen zusammenwachsen -> DevOps. Das geht nur auf der Basis von gegenseitigem Vertrauen, Informationsfluss und auch Lernbereitschaft.
„Automate everything“ – alles soll automatisiert werden:
Engpässe sollen identifiziert und eliminiert werden – stattdessen: Generierung von Mehrwerten, Transparenz – Prinzipien des Flow sollen realisiert werden.
Es müssen Bewertungskriterien geschaffen werden und auch ständig nachgemessen werden (Bsp. Non-functional requirements) – Antwortzeiten einer WebApplikation, Testabdeckung, Code-Verifizierung (Bsp: sonarcube).
Generell bringt es für das Unternehmen den größten Mehrwert, wenn das Wissen untereinander geteilt wird. Es muss eine Bereitschaft vorhanden sein, voneinander zu lernen.
– Softwarezyklus in DevOps
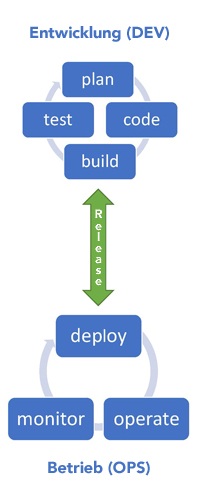
Wichtig ist bei der nachfolgenden Grafik:
Sowohl Dev wie auch Ops haben Ihren eigenen Kreislauf. Beide Kreisläufe sind über das Releasen von Softwarepaketen miteinander verbunden. Der Releasepfeil zeigt in beide Richtungen, so dass beide Kreisläufe immer wieder ineinanderfließen. Wenn etwas in der Produktion nicht funktioniert, fließt die Information sofort zur Entwicklung. Da Dev und Ops nun im selben Team arbeiten, wird diese Informationen zeitnah im Team diskutiert und es kann schnellst möglich eine angemessene Reaktion erfolgen.
– Vorteile des DevOps-Ansatzes
Geschwindigkeit
Prozesse werden beschleunigt – nach außen hin: die Kunden bekommen schneller, innovative Lösungen.
Zuverlässigkeit
Durch Automatisierung der Prozesse: Paketierung, Bereitstellung und Test wird eine Transparenz geschaffen. Zusätzlich ist dies der Grundstein für eine wiederholbare und letztlich weniger fehleranfällige Ausführung.
Skalierbarkeit
Durch den Einsatz von Virtualisierungstechnologien sind die Unternehmen in der Lage, schneller und qualitativ zu skalieren. Bei Engpässen wird nicht mehr ein neuer physischer Server gekauft. Stattdessen wird eine neue virtuelle Maschine aufgesetzt. Die Beschreibung der virtuellen Maschine ist heutzutage versionsverwaltet und in Form von Beschreibungssprachen hinterlegt – „infrastructure as code“. Der Vorteil dieses Ansatzes ist, dass beliebig viele identische Umgebungen, fehlerfrei in erheblich kürzerer Zeit aufgebaut werden können.
Verbesserte Zusammenarbeit
DevOps-Teams tragen eine gemeinsame Verantwortung für die Software sowohl in der Entwicklung wie auch im Betrieb.
Sicherheit
Die Qualität der Software wird aufgrund von automatisierten Tests steigen. Neben der bekannten Testpyramide: unit test, integration test, acceptance test entsteht hier gerade eine neue Bewegung: DevSecOps.
- Das DevOps Team soll hier im Rahmen der Zyklen auch die IT-Sicherheit integrieren – nach Möglichkeit auch automatisiert wie auch durch zusätzliche, dedizierte Manpower.
- Beispiele für DevSecOps
- automatisierte Code – Schwachstellenprüfung
- automatisierte security / penetration tests
- Definition von Quality Gates
- Auditing logging aller automatisierten Prozesse – Nachvollziehbarkeit
– DevOps Best Practises
Die folgenden DevOps Best Practises helfen dabei, die oben aufgeführten Vorteile zu realisieren:
Continuous Integration
- Wenn die Entwickler Code versionieren, erfolgt automatisch durch das Zusammenspiel von Versionsverwaltungssystem und einem CI-Server wie z.B. Jenkins ein automatisierter Prozess bestehend aus unit test, code quality check, packaging
- Der Code wird auf diese Weise kontinuierlich getestet. Das Paket wird stetig neu gebaut. Probleme bei der Integration von Code werden frühzeitig aufgedeckt und an die Entwickler zurückgemeldet (Feedback-Schleife)
Skalierbarkeit
Hier kann ebenfalls ein CI-Server wie Jenkins unterstützen, der automatisiert die Softwareartefakte nimmt und auf unterschiedlichste Zielplattformen automatisiert installiert.
Microservices
Ein Mikroservice ist ein Service, der idealerweise nur eine Sache erledigt und diese mit sehr hier Qualität. Eine Softwareapplikation besteht basierend auf einer Mircroservices-Architektur dann aus vielen Microservices die mittels Orchestrierung die Gesamtfunktionalität der Anwendung darstellen. Dies steht im Gegensatz zu einer monolithischen Applikation, welche aus einem großem Softwareartefakt besteht. Der Vorteil der Microservices ist an dieser Stelle, dass diese separat installiert werden können und somit neue Funktionalitäten bereitgestellt werden. Firmen wie Amazon und Netflix haben gezeigt, dass es möglich ist tausende von Deployments pro Tag durchzuführen und so die Funktionalitäten stetig zu aktualisieren / erweitern. Auch im Fehlerfall ist nicht die gesamte Funktionalität einer Applikation betroffen (nicht verfügbar), sondern nur ein Teil, repräsentiert durch einen Microservice.
Protokollierung / Monitoring
Die automatisierten Prozesse sollten eine Protokollierung beinhalten. Damit ist eine Nachvollziehbarkeit gegeben. Nur versionierte Artefakte dürfen prozessiert werden. Zusätzlich sollte ein Monitoring etabliert werden.
- APM – Application and performance monitoring
- Messung von Antwortzeiten, Datenbankzugriffe, Identifikation von Lastspitzen
- Tool: z.B. app dynamics, Dynatrace
- End-User-Monitoring
- Application logs / Verknüpfung APM-Monitoring
- Synthetic Monitoring
- Health check, liveness checks
- Verfügbarkeit der Applikation
- Unterstützung in WebApps durch Selenium, CI-Server
- Log-Monitoring
- Applikationslogs, Weberver-Logs, OS-Logs
- Identifikation, Zuordnung zu Servern ist wichtig
- Server-ID, Session-IDs, künstliche Transaktions-IDs
- Automatisiertes Einsammeln der Logs von allen Servern wenn die Anwendung im Cluster betrieben wird
- Tool: ELK-Stack – elastic search / kibana / stash
- OS-Monitoring
- Hardware-Metriken
- Baselines festlegen
Kollaboration: Zusammenarbeit und Kommunikation
Eine gute, bereichsübergreifende Kommunikation ist bildet die Basis für eine
DevOps-Unternehmenskultur
– Deployment-Pipeline
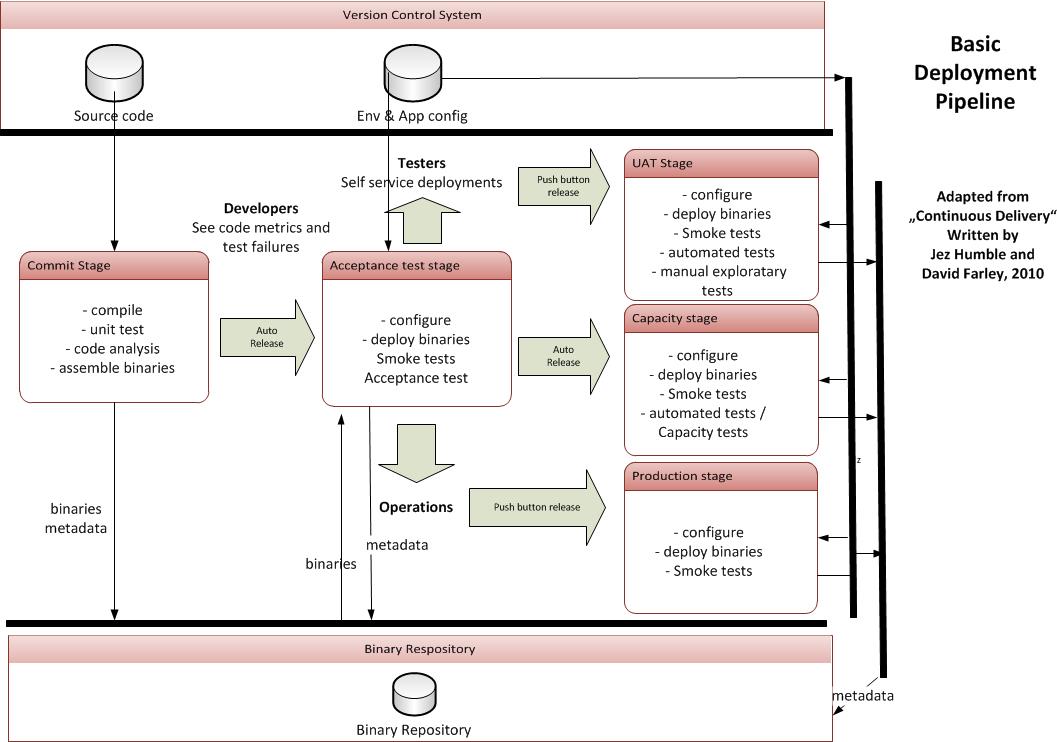
Die automatisierten Build- und Deploymentprozesse (Continuous Integration, Continuous Delivery) werden in der nachfolgenden Deployment Pipeline-visualisiert. Bei der dargestellten Pipeline handelt es sich um einen Vorschlag. Je nach Unternehmen und Projekterfordernis kann diese variieren. Die Stages: Commit, Acceptance Stage wie auch die Produktion sind als Minimalanforderung zu verstehen. Gegebenenfalls setzen Projekte je nach Bedarf auch weitere Stages auf.
Wichtig ist hier das Zusammenspiel:
Der Prozess beginnt mit einem Einchecken von Source-Code von einem Entwickler ins Versionsverwaltungssystem. Das Versionsverwaltungssystem ist mit einem CI-Server – Continuous Integration Server wie z.B. Jenkins verbunden. Der CI-Server ist in der Grafik aus Gründen der Übersichtlichkeit nicht mitaufgeführt.
Über eine WebHook teilt das Versionsverwaltungssystem dem CI-Server mit, dass Code neu versioniert wurde. Daraufhin zieht der CI-Server den neu versionierten Code aus dem Versionsverwaltungssystem und startet mit den in der Commit-Stage beschriebenen Aktionen.
Sind die Aktionen in der Commit-Stage alle erfolgreich verlaufen, startet der CI-Server erneut mit einem automatisierten Prozess. Er zieht die in der Commit-Stage generierten Binaries und die installiert diese in der Acceptance Test Stage. Des Weiteren holt der CI-Server die zugehörige Konfiguration aus dem Versionskontrollsystem und installiert diese ebenfalls.
Ein Fehler kann in der Commit-Stage z.B. die fehlgeschlagene Unit-Tests entstehen. Hier gibt es Möglichkeiten im CI-Server Schwellwerte zu definieren, die dann letztlich darüber entscheiden, in welche Aktion als nächstes folgt – Deployment in die nächste Stage oder Benachrichtigung an die Entwickler keine weiteren automatisierten Aktionen.
Von der Acceptance Test Stage geht es dann automatisiert weiter zur Capacity Stage.
Tester haben die Möglichkeit, sich eine Version auszuwählen und diese auf die UAT-Stage zu installieren und anschließend zu testen.

Andreas Kuhn
Senior IT Consultant